All the data for this project comes from the official Linked Open Data repository run by the Chamber of Deputies (Camera dei Deputati). The data gets updated in real time as Parliament does its work, which means we’re looking at a live picture of legislative activity.
We focused specifically on the XIX Legislature (started on October 13, 2022) which breaks the pattern of the last several years: there is a clear winner in the election, a stable majority, and the government is not mingled together from five different parties that cannot agree on legislatures. That makes it a useful case study for understanding how the Parliament behaves when it’s not constantly fighting.
2.2 Structure and Dimensions
The raw data isn’t structured, and comes as a semantic graph in RDF/XML format, which is a web of relationships between entities, not like a usual csv file. To work with it, we had to parse and flatten data into five separate dataframes using R:
votazione-19.rdf (Votes): The core dataset that contains the outcomes of parliamentary votes like metadata on the subjects (amendments, confidence votes etc.) and the aggregate tallies (Present, Voting, Ayes, Nays, Abstentions).
seduta-19.rdf (Sessions): The “calendar” of the Chamber which links every vote to a specific date, providing the temporal data to analyze the time of legislative work (Story II).
deputato-19.rdf (Deputies): The demographic registry of the 400 elected officials. It contains personal attributes such as gender, age, profession, and education levels (Story I).
elezione-19.rdf (Elections): it links individual deputies to their specific electoral colleges and constituencies, used for the spatial analysis across the North-South of Italy
gruppoParlamentare-19.rdf (Groups): A reference dictionary that maps internal group codes to the official names of Parliamentary Groups (Parties)
2.3 Data Quality and Challenges
Converting the data from RDF format into usable dataframes was one of the most tedious part of this project. RDF stores everything as triplets, which is useful for representing linked data but doesn’t translate easily into tables you need for analysis. We had to write custom parsing scripts to flatten the data out, and in some cases we had to manually reconstruct relationships that got lost in the process.
Another issue was that a lot of fields are just raw strings such as profession and level of education: these often came as free text rather than standardized categories. We spent a fair amount of time cleaning and standardizing these fields before we could do anything useful with them.
2.4 Missing Data and NAs
Because our data comes from RDF triplets rather than a neat Excel spreadsheet, “missing values” here don’t just mean empty cells. They often represent missing links in the web of data or optional fields that were left blank.
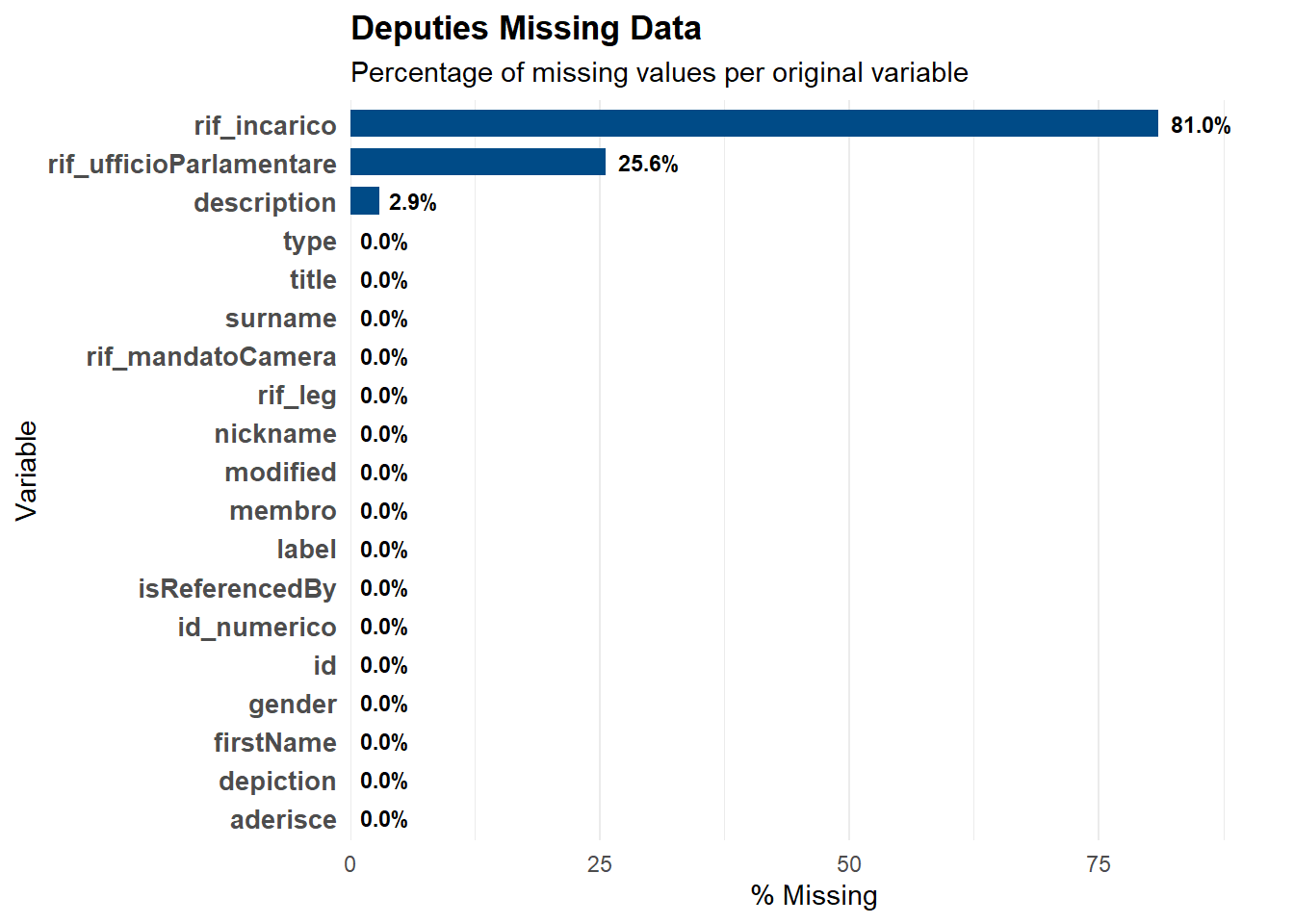
Undeclared Personal Information: the description field is supposed to be a catch-all for biographical info, like education and previous jobs. But since deputies aren’t forced to share this, many simply don’t.
Structural NAs: we also found plenty of missing values in technical columns, but these are actually reflections of how the Parliament works. Some deputies get elected in single-member districts, where they run as part of a coalition rather than a single party: these deputies don’t have a direct parliamentary office (rif_ufficioParlamentare) link. Similalry the majority of the deputy is a standard member of the assembly and doesn’t hold a special leadership role (rif_incarico), like Committee President or Questore.
The data is publicly available through the dati.camera.it portal under an Open Data license (CC-BY 4.0). While the Chamber provides the raw RDF dumps, we transformed these triplets into R dataframes manually.